


Работа със символни низове
Много често програмите трябва да обработват данни, които са в текстов формат. Вече имаше примери за слепване на два низа с оператора +, но могат да се извършват много повече операции. Могат да се извличат части от низ, да се добавят и премахват интервали, да преобразуват малки в главни букви и обратно, да се проверява дали низ е с подходящ формат. С Python код може дори да се копира или поставя текст.
Тази глава обяснява всичко това. След това има два отделни проекта: прост клипборд, в който се пазят няколко текстови низа, и програма, автоматизираща скучната задача по форматиране на части от текст.
Работа с низове
Следва описание на начините, по които в Python код може да се създават, показват и достъпват низове.
Низови литерали
Низовите стойности се създават сравнително лесно: те започват и завършват с единична кавичка. Тук възниква въпросът - как да се използва кавичка в низ? Не може да се напише 'Тази котка се казва 'Шери'', защото според Python низът завършва след казва , а остатъка (Шери'') е невалиден код. За радост има няколко начина, по които да се създава низ.
Двойни кавички
Низовете могат да започват и завършват с двойни кавички, точно както с единични. Една от ползите на използването на двойни кавички е възможността за използване на символа за единични в тях. Пример от интерактивната конзола:
>>> spam = "Тази котка се казва 'Шери'"
Този низ започва с двойна кавичка и Python знае, че единичната кавичка е част от низа, а не отбелязва края му. В случай, че се налага използване и на единични, и на двойни кавички в един низ, ще трябва да се използват екраниращи символи.
Екраниращи символи
Употребата на екраниращ символ (escape character, наричан още управляваща последователност) позволява в низ да се използва символ, който по принцип е невъзможен за добавяне. Той се състои от обратна наклонена черта (\ , backlash), последван от символът, който ще се добави в низа. Например екранирането на единична кавичка се постига с \'. Така може да се използва единична кавичка в низ, който започва и завършва с единична кавичка. Пример от интерактивната конзола за употрбата на екраниращ символ:
>>> spam = 'Тази котка се казва \'Шери\''
Python знае, че единичните кавички в \'Шери\' са с обратна наклонена черта, така че те не означават край на низа. Екраниращите символи \' и \" позволяват използването в низ на съответно единична и двойна кавичка.
Следващата таблица показва наличните екраниращи символи:
| Последователност | Принтира |
| \' | Единична кавичка |
| \" | Двойна кавичка |
| \t | Табулация |
| \n | Нов ред |
| \\ | Обратна наклонена черта |
Пример от интерактивната конзола:
>>> print("Здравей!\nКак се казваш?\nд\'Артанян")
Буквални низове
При използване на r преди началната кавичка на стринг той се превръща в буквален низ. Буквалният низ (raw string) напълно игнорира всички екраниращи символи и принтира всички обратни наклонени черти, които са в низа. Пример от интерактивната конзола:
>>> print(r'Тази котка се казва \'Шери\'')
Тази котка се казва \'Шери\'
Принтира се буквален низ, така че за Python обратните наклонени черти са част от низа, а не екраниращ символ. Такива низове са полезни при въвеждането на низови стойности, които съдържат много обратни наклонени черти. Примери за подобни низове са файловите пътища в Windows (r'C:\Users\Stanimir\Desktop') или регулярните изрази от следващата глава.
Многоредови низове с тройни кавички
За добавяне на нов ред в низ може да се използва екраниращ символ\n, но често е по-лесно използването на многоредови низове. В Python многоредов низ започва и завършва с три единични или три двойни кавички. Всички символи между "тройните кавички" се смятат за част от низ, включително кавички, табулации и нови редове. Правилата за отместването на блоковете не важат за редовете в многоредовия низ. Следва примерна програма pismo.py:
print('''Здравей, Наде.
Да се срещнем в сладкарница 'Нашата' утре в 11:00 ?
Поздрави,
Станимир.
''')
При изпълнението на програмата се получава следния резултат:
Здравей, Наде.
Да се срещнем в сладкарница 'Нашата' утре в 11:00 ?
Поздрави,
Станимир.
За отбелязване е че не е необходимо кавичките на 'Нашата' да се екранират. Екранирането на единичните и двойните кавички в многоредов низ е по желание. Следващото изникване на print() принтира същият текст, но не използва многоредов низ:
>>> print('Здравей, Наде.\n\nДа се срещнем в сладкарница \'Нашата\' утре в 11:00 ?\n\nПоздрави,\nСтанимир.')
Многоредови коментари
Символът диез (#, решетка) отбелява началото на коментар, който стига до края на реда. За коментар, който е дълъг няколко реда по-често се използва многоредов низ. Следва напълно валиден Python код:
"""Това е тестова Python програма.
Написана от Станимир avtomatizirane@gmail.com
Тази програма е направена за Python 3, а не Python 2
"""
def spam():
"""Това е многоредов коментар, който
описва какво прави функцията spam()."""
print('Здравей!')
Индексиране и разрязване на низове
Низовете използват индекси и разрези по същия начин, както списъците. Представата за низ може да е като списък, в който всеки символ заема поредната позиция. Пример с низа 'Здравей, свят!':
' З д р а в е й , с в я т ! ' 0 1 2 3 4 5 6 7 8 9 10 11 12 13Интервалът и удивителният знак са включени в броя символи, така че 'Здравей, свят!' е дълъг 14 символа, З на позиция 0 до ! на позиция 13.
Пример от интерактивната конзола:
>>> spam = 'Здравей, свят!'
>>> spam[0]
'З'
>>> spam[4]
'в'
>>> spam[-1]
'!'
>>> spam[0:7]
'Здравей'
>>> spam[:7]
'Здравей'
>>> spam[9:]
'свят!'
По зададен индекс може да се получи символът на тази позиция в низа. Стартовият индекс от зададен интервал е включен, а крайния индекс не е. По тази причина при spam със стойност 'Здравей, свят!', резултатът от spam[0:7] е 'Здравей'. Частта от низа, която се получава с spam[0:7], включва всичко от spam[0] до spam[6], без запетаята на позиция 7 и интервала на позиция 8. По подобен начин range(5) в цикъл for ще извърти стойностите до, но не включително, 5.
Разрязването на низ не променя първоначалния низ. Разрезът може да се запише в отделна променлива. Пример от интерактивната конзола:
>>> spam = 'Здравей, свят!'
>>> fuzz = spam[0:7]
>>> fuzz
'Здравей'
Записването на резултата от разрез в друга променлива е удобен начин за достъпване едновременно на целия низ и на част от него.
Използване на операторите in и not in с низове
Операторите in и not in могат да се използват с низове, по съвсем същия начин, като с списъчни стойности. Израз с два низа, с in или not in между тях, се пресмята до булева стойност True или False. Пример от интерактивната конзола:
>>> 'Здравей' in 'Здравей, свят'
True
>>> 'Здравей' in 'Здравей'
True
>>> 'ЗДРАВЕЙ' in 'Здравей, свят'
False
>>> '' in 'тест'
True
>>> 'котки' not in 'котки и кучета'
False
Тези изрази проверяват дали първият низ (точно същият низ, със значение на малки и големи букви) може да се намери във втория низ.
Доавяне на низ в друг низ
Добавянето на низ в друг низ е често срещана операция в програмирането. До сега се използваше операторът + за слепване на низове:
>>> name = 'Станимир'
>>> age = 4000
>>> 'Здравей, казвам се ' + name + '. На ' + str(age) + ' години съм.'
'Здравей, казвам се Станимир. На 4000 години съм.'
Този начин изисква много досадно писане. По-прост подход е използването на форматиращи низове (string interpolation). Те представляват низове-шаблони, в които операторът %s се използва като маркер, който се заместв със стойностите, които следват низа. Едно предимство на използването на форматиращи низове е отпадането на необходимостта от използването на str() за преобразуване на стойностите в низове. Пример от интерактивната конзола:
>>> name = 'Станимир'
>>> age = 4000
>>> 'Здравей, казвам се %s. На %s години съм.' %(name, age)
'Здравей, казвам се Станимир. На 4000 години съм.'
Python версия 3.6 добави нов тип форматиращи низове, f-strings. Те са подобни на предишните, но вместо %s се използват скоби, като изразите са поставени директно в скобите. Тези низове се отбелязват с префикс f преди началната кавичка (подобно на буквалните низове). Пример от интерактивната конзола:
>>> name = 'Станимир'
>>> age = 4000
>>> f'Здравей, казвам се {name}. Догодина ще стана на {age + 1} години.'
'Здравей, казвам се Станимир. Догодина ще стана на 4001 години.'
Не трябва да се пропуска префикса f. В противен случай скобите и тяхното съдържание ще са просто част от низа:
>>> 'Здравей, казвам се {name}. Догодина ще стана на {age + 1} години.'
'Здравей, казвам се {name}. Догодина ще стана на {age + 1} години.'
Полезни низови методи
Някои низови методи анализират низовете, други създават нови низове с трансформиране на съществуващи низове. Тази секция описва най-често използваните методи
Методите upper(), lower(), isupper() и islower()
Методите upper() и lower() връщат нов низ, в който всички букви от първоначалния низ са преобразувани съответно до главна или малка. Небуквените символи остават непроменени. Пример от интерактивната конзола:
>>> spam = 'Здравей, свят!'
>>> spam = spam.upper()
>>> spam
'ЗДРАВЕЙ, СВЯТ!'
>>> spam = spam.lower()
>>> spam
'здравей, свят!'
Тези методи не променят самия низ, а връщат нова низова стойност. За промяна на първоначалния низ трябва резултатът от извикването на upper() или lower() да се присвои на същата променлива. По тази причина трябва да се използва spam = spam.upper(), за да се промени низа в spam, вместо само spam.upper(). Това е като променливата eggs да съдържа стойност 10. eggs + 3 не променя стойността на eggs, но eggs = eggs + 3 я променя.
Методите upper() и lower() са полезни при сравнения, когато регистъра (малка или главна) на буквите не е от значение. Например низовете 'добре' и ДОБре не са равни. Но в следващата програма няма значение дали потребителят юе въведе Добре, ДОБРЕ или доБРЕ, защото низът се преобразува в малки букви.
print('Как си?')
feeling = input()
if feeling.lower() == 'добре':
print('И аз съм добре.')
else:
print('Надявам се да се оправиш.')
При изпълняние на програмата се показва въпросът. Въвеждането на който и да е вариант на добре, примерно ДОБре, ще доведе до принтиране на И аз съм добре.. Добавянето на код в програмата, който обработва варианти или грешки във въведените от потребителя данни(като неправилни главни букви), я прави по-лесна за използване и намаля вероятността за грешки.
Как си?
ДОБре
И аз съм добре.
Методите isupper() и islower() връщат булева стойност True, ако в низа има поне една буква и всички букви са съответно главни или малки. Иначе методът връща False. Пример от интерактивната конзола:
>>> spam = 'Здравей, свят!'
>>> spam.islower()
False
>>> spam.isupper()
False
>>> 'ЗДРАВЕЙ'.isupper()
True
>>> 'абв12345'.islower()
True
>>> '12345'.islower()
False
>>> '12345'.isupper()
False
Методите upper() и lower() връщат низове, така че на тези върнати низове могат също да се викат методи. Такива изрази приличат на навързани извиквания на методи. Пример от интерактивната конзола:
>>> 'Здравей'.upper()
'ЗДРАВЕЙ'
>>> 'Здравей'.upper().lower()
'здравей'
>>> 'Здравей'.upper().lower().upper()
'ЗДРАВЕЙ'
>>> 'ЗДРАВЕЙ'.lower()
'здравей'
>>> 'ЗДРАВЕЙ'.lower().islower()
True
Методите isX()
Има още няколко низови метода, чиито имена започват с is, подобно на islower() и isupper(). Тези методи връщат булев резултат, описващ съдържанието на низа. Някои от по-често срещаните isX низови методи:
isalpha() Връща True ако низът се състои само от букви и не е празен
isalnum() Връща True ако низът се състои само от букви и цифри и не е празен
isdecimal() Връща True ако низът се състои само от цифри и не е празен
isspace() Връща True ако низът се състои само от интервали, табулации и нови редове и не е празен
istitle() Връща True ако низът се състои само от думи, които започват с главна буква, следвана от само малки букви(Използва се в заглавията на английски език)
Пример от интерактивната конзола:
>>> 'Здравей'.isalpha()
True
>>> 'Здравей123'.isalpha()
False
>>> 'Здравей123'.isalnum()
True
>>> 'Здравей'.isalnum()
True
>>> '123'.isdecimal()
True
>>> ' '.isspace()
True
>>> 'Всяка Дума Главна Буква'.istitle()
True
>>> 'Всяка Дума Главна Буква 123'.istitle()
True
>>> 'Всяка Дума не Главна Буква'.istitle()
False
>>> 'Всяка Дума Също НЕ Главна Буква'.istitle()
False
Методите isX() са полезни за валидиране на потребителски данни. Пример е следващата програма validateInput.py. Тя многократно пита потребителя за възсраст и парола, докато не се предоставят валидни данни.
while True:
print('Въведи възраст:')
age = input()
if age.isdecimal():
break
print('Възрастта трябва да е число.')
while True:
print('Избери парола (само букви и числа):')
password = input()
if password.isalnum():
break
print('Паролите могат да съдържат само букви и числа.')
С първия while цикъл програмата пита потребителя за възрастта му, като въведеното се записва в age. След това се проверява дали age е валидна (числова) стойност. В такъв случай while цикълът се прекъсва и се продължава към втория цикъл, който пита за парола. Иначе потребителят вижда съобщение, че трябва да въведе число, и цикълът прави ново завъртане. Във втория while цикъл потребителят трябва да въведе парола, която се записва в password. Цикълът прекъсва, ако въведената парола е буквено-цифрова комбинация. Ако не е - показва се съобщение за позволените символи в парола, след това цикълът се завърта отново.
При използване на програмата се получава подобен резултат:
Въведи възраст:
четиридесет и две
Възрастта трябва да е число.
Въведи възраст:
42
Избери парола (само букви и числа):
пар0ла!
Паролите могат да съдържат само букви и числа.
Избери парола (само букви и числа):
пар0ла
Методите startswith() и endswith()
Методите startswith() и endswith() връщат True, ако низът, на който са извикани, съответно започва или завършва с низа, подаден на метода. В противен случай се връща False. Пример от интерактивната конзола:
>>> 'Здравей, свят!'.startswith('Здравей')
True
>>> 'Здравей, свят!'.endswith('свят!')
True
>>> 'абв123'.startswith('абвгде')
False
>>> 'абв123'.endswith('12')
False
>>> 'Здравей, свят!'.startswith('Здравей, свят!')
True
>>> 'Здравей, свят!'.endswith('Здравей, свят!')
True
Тези методи са полезна алтернатива на оператора за равно ==. С тях може да се провери дали първата или последната част от низ е равна на друг низ, а не само да се сравняват цели низове.
Методите join() и split()
Методът join() е полезен за събиране на списък от низове в един нов низ. Методът join() се извиква на даден низ, приема като параметър списък от низове и връща низ. Върнатият низ е резултатът от слепването на всеки низ от подадения списък. Пример от интерактивната конзола:
>>> ', '.join(['котки', 'кучета', 'мишки'])
'котки, кучета, мишки'
>>> ' '.join(['Казвам', 'се', 'Станимир'])
'Казвам се Станимир'
>>> 'АБВ'.join(['Казвам', 'се', 'Станимир'])
'КазвамАБВсеАБВСтанимир'
Низът, на който се извиква join(), се добавя между низовете от списъка. Когато на низа ', ' се извиква join(['котки', 'кучета', 'мишки']), резултатът е низа 'котки, кучета, мишки'.
Методът join() се извиква на низ и получава списък (лесно в инцидентно да се извика наобратно). Методът split() върши обратното - той се вика на низ и връща списък с низове. Пример от интерактивната конзола:
>>> 'Казвам се Станимир'.split()
['Казвам', 'се', 'Станимир']
По подразбиране низът 'Казвам се Станимир' се разделя от всеки "празен" символ, като интервал, табулация или нов ред. Тези "празни" символи не се включват в низовете от върнатия списък. На метода split() може да се подаде низ, който да се използва като разделител. Пример от интерактивната конзола:
>>> 'КазвамАБВсеАБВСтанимир'.split('АБВ')
['Казвам', 'се', 'Станимир']
>>> 'Казвам се Станимир'.split('м')
['Казва', ' се Стани', 'ир']
Честа употреба на split() е за разделяне на многоредов низ с използване на символа за нов ред. Пример от интерактивната конзола:
>>> spam = '''Скъпа Надя,
Как си? Аз съм добре.
Има кутия в хладилника
с етикет "Млечен експеримент"
Моля, не го пий.
Поздрави,
Станимир.'''
>>> spam.split('\n')
['Скъпа Надя,', 'Как си? Аз съм добре.', 'Има кутия в хладилника', 'с етикет "Млечен експеримент"', '', 'Моля, не го пий.', 'Поздрави,', 'Станимир.']
Подаването на аргумент '\n' на split() позволява разделянето на многоредовия низ. Всеки ред от низа е елемент във върнатия списък.
Разделяне на низове с метода partition()
Методът partition()разделя низ на текста преди и текста след даден низ разделител. Този метод се извиква на низ, в който търси подадения низ разделител. Връща комплект с три низови стойности - низовете "преди", "разделител" и "след". Пример от интерактивната конзола:
>>> 'Здравей, свят!'.partition('с')
('Здравей, ', 'с', 'вят!')
>>> 'Здравей, свят!'.partition('свят')
('Здравей, ', 'свят', '!')
Ако разделителят, подаден на partition(), се среща няколко пъти в низа, на който partition() е извикан, методът разделя низа на първото място:
>>> 'Здравей, свят!'.partition('в')
('Здра', 'в', 'ей, свят!')
Ако разделителя го няма, първия низ в комплета ще е целия оригинален низ, а останлите два ще са празни:
>>> 'Здравей, свят!'.partition('АБВ')
('Здравей, свят!', '', '')
Трите върнати низа могат да се присвоят на три променливи с използване на множествено присвояване:
>>> before, sep, after = 'Здравей, свят!'.partition(' ')
>>> before
'Здравей,'
>>> after
'свят!'
Методът partition() е полезен за разделяне на низ, когато са необходими частите преди и след даден низ разделител.
Подравняване на текст с методите rjust(), ljust() и center()
Низовите методи rjust() и ljust() връщат допълнена версия на низа, на който са извикани. За подравняване на текста се използват интервали. Първият аргумент на двата метода е целочислена дължина на подравнения низ. Пример от интерактивната конзола:
>>> 'Здравей'.rjust(10)
' Здравей'
>>> 'Здравей'.rjust(20)
' Здравей'
>>> 'Здравей, свят'.rjust(20)
' Здравей, свят'
>>> 'Здравей'.ljust(10)
'Здравей '
'Здравей'.rjust(10) казва - "Искам да подравня вдясно 'Здравей' в низ с обща дължина 10." 'Здравей' е пет символа, така че отляво се добавят три символа. Резултатът е низ с 10 символа, като 'Здравей' е вдясно.
Методите rjust() и ljust() могат да приемат незадължителен втори аргумент, който задава запълващ символ, различен от интервал. Пример от интерактивната конзола:
>>> 'Здравей'.rjust(20, '*')
'*************Здравей'
>>> 'Здравей'.ljust(20, '-')
'Здравей-------------'
Низовият метод center() е подобен на rjust() и ljust(), но центрира текста, вместо да го подрявнява вляво или вдясно. Пример от интерактивната конзола:
>>> 'Здравей'.center(20)
' Здравей '
>>> 'Здравей'.center(20, '=')
'======Здравей======='
Тези методи са особено полезни при принтиране на таблични данни. Пример с програма, записана като picnicTable.py:
def printPicnic(itemsDict, leftWidth, rightWidth):
print('Пикник провизии'.center(leftWidth + rightWidth, '-'))
for k, v in itemsDict.items():
print(k.ljust(leftWidth, '.') + str(v).rjust(rightWidth))
picnicItems = {'сандвичи': 4, 'ябълки': 12, 'лимонади': 4, 'бисквитки': 8000}
printPicnic(picnicItems, 12, 5)
printPicnic(picnicItems, 20, 6)
В тази програма се дефинира метод printPicnic(), който приема речник с информация и използва center(), ljust() и rjust() за показване на информацията в удобно подравнено подобие на таблица.
Подаваният на printPicnic() речник е picnicItems. В picnicItems има 4 сандвича, 12 ябълки, 4 лимонади и 8000 бисквитки. Тази информация може да се организира в две колони, с името на продукта отляво и количеството вдясно.
За да се подравни текста е необходимо да се знае колко широка трябва да е лявата и дясната колона. Тези ширини се подават на printPicnic().
Самата функция printPicnic()приема речник, leftWidth - ширина на лявата колона, и rightWidth - ширина на дясната колона в таблицата. Функцията принтира заглавие Пикник провизии, центрирано над таблицата. След това функцията превърта всички елементи в речника, принтирайки на нов ред всяка двойка ключ-стойност. Ключът е подравнен вляво, запълнен с точки, а стойността е подравнена вдясно и допълнена с точки.
След дефиниране на printPicnic() се дефинира речника picnicItems. Слдват две извиквания на printPicnic(), с различни ширини на лявата и дясната колона.
При изпълнение на програмата провизиите се принтират два пъти. Първият път лявата колона е широка 12 символа, а дясната колона е широка 5 символа. Вторият път колоните са широки съответно 20 и 6 символа.
-Пикник провизии-
сандвичи.... 4
ябълки...... 12
лимонади.... 4
бисквитки... 8000
-----Пикник провизии------
сандвичи............ 4
ябълки.............. 12
лимонади............ 4
бисквитки........... 8000
Използването на rjust(), ljust() и center() позволяват подравнено подреждане на низовете, дори да не се знае колко символа са дълги те.
Премахване на невидими символи с strip(), rstrip() и lstrip()
Понякога се налага премахване на невидимите символи (интервал, табулация, нов ред) в началото, в края или от двете страни на даден низ. Низовият метод strip() връща нов низ без никакви невидими символи в началото или в края. Методите lstrip() и rstrip() премахват невидимите символи съответно в левия или десния край. Пример от интерактивната конзола:
>>> spam = ' Здравей, свят '
>>> spam.strip()
'Здравей, свят'
>>> spam.lstrip()
'Здравей, свят '
>>> spam.rstrip()
' Здравей, свят'
Методите могат да приемат като аргумент низ, който определя кои символи да се премахнат в краищата. Пример от интерактивната конзола:
>>> spam = 'ХейХейПилеХейЯйцаХейХей'
>>> spam.strip('ейХ')
'ПилеХейЯйца'
Подаването на аргумент 'ейХ' на strip() указва, че функцията ще премахне всички срещания на е, й и Х от краищата на низа в spam. Не е от значение редът на символите в низа, който се подава на strip() - резултатът от strip('ейХ') е същият като на strip('йеХ') или strip('Хей').
Числова стойност на символ с функциите ord() и chr()
Компютрите съхраняват информацията като байтове - поредици от двоични числа. Това означава, че трябва по някакъв начин текста да се преобразува в числа. По тази причина за всеки текстов символ е определена съответстваща числова стойност, наречена Уникод кодова точка (Unicode code point). Например числения код на 'A'(латинска буква главно "А", буквата "А" на кирилица е с друг код) е 65, на '4' е 52, а на '!' е 33. Функцията ord() връща кодовата точка на подадения едносимволен низ. Функцията chr() връща едносимволен низ, отговарящ на подадената целочислена кодова точка. Пример от интерактивната конзола, в който се използва буква на кирилица:
>>> ord('A')
1040
>>> ord('4')
52
>>> ord('!')
33
>>> chr(1040)
'А'
Тези функции са полезни при необходимост за подреждане на символи. Също така могат да помогнат за изпълнение на математически операции върху символи:
>>> ord('Б')
1041
>>> ord('А') < ord('Б')
True
>>> chr(ord('А'))
'А'
>>> chr(ord('А') + 1)
'Б'
Уникод и кодовите точки са много обширна тема, чиито подробности не са предмет на тази книга. В интернет може да се намери повече информация по тази тема.
Копирне и поставяне на низове с модула pyperclip
Модулът pyperclip() има функции copy() и paste(), които изпращат и получават текст от компютърния клипборд. Копирането на резултата от изпълнението на програмата е лесен начин за поставянето му в имейл, документ или друг софтуер.
Модулът pyperclip не е включен в Python. За инсталирането му трябва да се следват упътванията за инсталиране на външни модули. Пример от интерактивната конзола (pyperclip трябва да е инсталиран) :
>>> import pyperclip
>>> pyperclip.copy('Здравей, свят!')
>>> pyperclip.paste()
'Здравей, свят!'
Разбира се, може да се копира и извън програмата. Например, ако се извика paste() след копиране на това изречение, ще има следния резултат:
>>> pyperclip.paste()
'Например, ако се извика paste() след копиране на това изречение, ще има следния резултат:'
Проект: Автоматично копиране на съобщение
Понякога има голям брой имейли, на които трябва да се отговаря с еднотипни фрази. Това означава доста повтарящо се писане. Може да се направи текстов документ с тези отговори, така че лесно да се копират и поставят. Но клипборда пази само по едно съобщение, което не винаги е удобно. Процесът може да се услесни с написването на програма, която пази няколко фрази.
Стъпка 1: Дизайн на програмата и структурите от данни
Трябва програмата да може да приеме аргумент, който ще е кратък ключ - например съгласен или зает. Към всеки ключ ще има асоциирано по-дълго съобщение. Това съобщение ще се копира, така че потребителят да може да го постави в имейла. Така потребителят може да има дълги подробни съобщения, без да се налага да ги пише всеки път.
Започва се с нов прозорец на файловия редактор. Програмата се записва като mclip.py. Програмата започва с #! (shebang) ред (подробности в Допълнение Б), следван от коментар, кратко описание на програмата. Всеки текст ще се асоциира с някакъв ключ, така че е подходящо използването на речник. Речникът ще е основната структура от данни, в която се съхраняват ключовете и фразите към тях. В началото програмата трябва да изглежда по подобен начин:
#! python3
# mclip.py - Множествен клипборд
TEXT = {'съгласен': """Да, съгласен съм. Звучи добре.""",
'зает': """Съжалявам, може ли да го отложим за следващата седмица?""",
'оферта': """Желаете ли да направите ежемесечно дарение?"""}
Стъпка 2: Работа с аргументите от командния ред
Аргументите от командния ред са записани в променливата sys.argv. (В Допълнение Б за повече информация за използването на аргументи от командния ред). Първият елемент в списъка sys.argv винаги е низ, съдържащ името на файла, в който е записана програмата ('mclip.py'). Вторият елемент е първия аргумент от командния ред. В тази програма аргументът е ключът на съобщението, което е необходимо. Аргументът от командния ред е задължителен, така че програмата показва съобщение за правилната употреба, ако липсва аргумент. Проверката е дали sys.argv съдържа по-малко от две стойности. В момента програмата изглежда по този начин:
#! python3
# mclip.py - Множествен клипборд
TEXT = {'съгласен': """Да, съгласен съм. Звучи добре.""",
'зает': """Съжалявам, може ли да го отложим за следващата седмица?""",
'оферта': """Желаете ли да направите ежемесечно дарение?"""}
import sys
if len(sys.argv) < 2:
print('Употреба: python mclip.py [ключ] - копира съобщението за този ключ')
sys.exit()
keyphrase = sys.argv[1]
Стъпка 3: Копиране на правилното съобщение
Ключът е записан като низ в променливата keyphrase. Трябва да се провери дали съществува такъв ключ в речника TEXT. Ако го има - стойността за този ключ се копира с помощта на pyperclip.copy(). (За използване на модула pyperclip той трябва да се импортира.). Променливата keyphrase реално не е необходима. Вместо нея може навсякъде в програмата да се използва sys.argv[1]. Но променлива с име keyphrase прави кода много по-четим от странното sys.argv[1].
В момента програмата изглежда по този начин:
#! python3
# mclip.py - Множествен клипборд
TEXT = {'съгласен': """Да, съгласен съм. Звучи добре.""",
'зает': """Съжалявам, може ли да го отложим за следващата седмица?""",
'оферта': """Желаете ли да направите ежемесечно дарение?"""}
import sys, pyperclip
if len(sys.argv) < 2:
print('Употреба: python mclip.py [ключ] - копира съобщението за този ключ')
sys.exit()
keyphrase = sys.argv[1]
if keyphrase in TEXT:
pyperclip.copy(TEXT[keyphrase])
print('Текстът за ' + keyphrase + ' е копиран.')
else:
print('Няма текст за ключ: ' + keyphrase)
Новият код търси ключът в речника TEXT. При наличие на такъв ключ - стойността за този ключ се копира и се показва съобщение. Ако няма такъв ключ - показва се съобщение, че няма ключ с такова име.
Това е завършения скрипт. Вече има бърз начин за копиране на различни съобщения (в Допълнение Б има инструкции за лесно изпълнение на програми от командния ред ). За добавяне на ново съобщение трябва да се промени речникът TEXT във файла с програмата.
При използване на Windows може да се създаде batch file, с който тази програма може да се изпълянва с WIN-R прозореца. (В Допълнение Б има повече информация за batch файловете). В нов файл се въвъежда:
@py.exe C:\path_to_file\mclip.py %*
@pause
Файлът се записва с име като mclip.bat в папката C:\Windows
След създаването на този файл използването на програмата с Windows се състои от натискане на WIN-R и написване на mclip ключ.
Проект: Добавяне на водещи символи в Уикипедия
При редактиране на статии в Уикипедия може да се добави списък с водещи символи. За получаване на такъв списък трябва всеки елемент да е на нов ред със звезда отпред. Но ако има наистина голям списък, добавянето на звезда в началото на всеки ред ще е много досадна задача. Но тя може да се автоматизира с кратка Python програма.
Скриптът bulletPointAdder.py взема копирания в клипборда текст, добавя звезда и интервал в началото на всеки ред и копира в клипборда новия текст. Например ако има копиран следния текст (нужен за статията в Уикипедия "Списък на списъците" )
Списък на реките в България
Списък на пещерите в България
Списък на селата в България
Списък на университетите в България
след изпълнението на програмата bulletPointAdder.py в клипборда трябва да има копиран следния текст:
* Списък на реките в България
* Списък на пещерите в България
* Списък на селата в България
* Списък на университетите в България
Този текст е готов за поставяне в статия от Уикипедия, където ще изглежда като списък с водещи символи.
Стъпка 1: Копиране и поставяне на текст
Програмата трябва да върши следното:
- Взема копирания в клипборда текст.
- Преработва го.
- Копира новия текст в клипборда.
Втората стъпка е малко неясна, но стъпки 1 и 3 са лесни - те са просто извикване на функциите pyperclip.copy() и pyperclip.paste(). В началото програмата ще съдържа само частта със стъпки 1 и 3. Ето първия вариант на програмата, записана като bulletPointAdder.py:
#! python3
# bulletPointadder.py - Добавя водещи символи в началото
# на всеки ред от копирания текст
import pyperclip
text = pyperclip.paste()
# TODO: Разделяне на редове и добавяне на звезди.
pyperclip.copy(text)
Коментарът TODO (от английски to do - да свършва) в напомняне, че тази част от програмата е за довършване. Може да се напише и по друг начин, но изразът TODO е възприет като стандартен в програмирането. Следващата стъпка е същинското имплементиране (осъществяване, написване) на тази част от програмата.
Стъпка 2: Разделяне на текста на редове и добавяне на звезда
Извикването на pyperclip.paste() връща целия копиран текст като един голям низ. Низът, записан в text, би изглеждал по следния начин (ако се използва примера "Списък на списъците"):
'Списък на реките в България\nСписък на пещерите в България\nСписък на селата в България\nСписък на университетите в България'
В низа има символи за нов ред \n, така че той би се принтирал на няколко реда. В тази низова стойност има много "редове". Трябва в началото на всеки ред да се добави звезда.
Може да се напише код, който намира всеки символ за нов ред \n и добавя звезда след него. Но по-лесно ще е да се използва метода split(), който да върне списък от низове. Всеки елемент от този списък ще е един ред от първоначалния низ. След това се добавя звезда в началото на всеки низ от списъка. Програмата ще изглежда по следния начин:
#! python3
# bulletPointadder.py - Добавя водещи символи в началото
# на всеки ред от копирания текст
import pyperclip
text = pyperclip.paste()
# Разделяне на редове и добавяне на звезди.
lines = text.split('\n')
for i in range(len(lines)): # преминаване през всички индекси в списък "lines"
lines[i] = '* ' + lines[i] # добавя звезда в началото на всеки низ от списъка "lines"
pyperclip.copy(text)
Текстът се разделя по новите редове и се получава списък, в който всеки елемент е едни ред от текста. Списъкът се запазва в lines. След това се преминава през всички елементи в lines. На всеки ред се добавя звезда в началото. Сега всеки низ в lines започва със звезда.
Стъпка 3: Съединяване на променените редове
Сега списъка linesсъдържа променените редове, всеки започващ със звезда. Но pyperclip.copy()примеа само една низова стойност, а не списък от низове. Списъкът lines се подава на метода join(), който връща един низ, съставен от съединените низове от списъка. Програмата ще изглежда по следния начин:
#! python3
# bulletPointadder.py - Добавя водещи символи в началото
# на всеки ред от копирания текст
import pyperclip
text = pyperclip.paste()
# Разделяне на редове и добавяне на звезди.
lines = text.split('\n')
for i in range(len(lines)): # преминаване през всички индекси в списък "lines"
lines[i] = '* ' + lines[i] # добавя звезда в началото на всеки низ от списъка "lines"
text = '\n'.join(lines)
pyperclip.copy(text)
При изпълнение на програмата тя ще замени копирания текст с текст, в който всеки ред започва със звезда. Сега програмата е завършена и може да бъде пробвана като се изпълни след копиране на някакъв текст.
Това е само един специфичен пример. Може да не се налага автоматизирането на точно тази задача, а на друга, която включва обработването на текст. Примери за подобни задачи са премахване на интервали в края на редовете или подмяна на малки и главни букви. В такива случаи може да се използва клипборда за предаване текста и получаване на обработената версия.
Кратка програма: Шифровано съобщение
Тази програма е вдъхновена от Pig Latin, измислен език, получен от промяна на думите в английския език. Такъв тип език може да се използва за предаване на шифрирани съобщения. Шифърът има прости правила. Ако думата започва с гласна, в края на думата се добавя йей . Ако думата започва със съгласни (една или повече), съгласните се местят в края на думата и след тях се добавя ей.
Ще се напише програма, която да дава следния резултат:
Въведи съобщение, което да се шифрова:
Моето име е СТАНИМИР и съм на 4000 години.
Оетомей имейей ейей АНИМИРСТЕЙ ийей ъмсей аней 4000 одинигей.
Програмата работи с промяна на низа, използвайки методите от тази глава. Следва и кода на самата програма, записана като shifar.py
# Шифроване на съобщение
print('Въведи съобщение, което да се шифрова:')
message = input()
VOWELS = ('а', 'ъ', 'о', 'у', 'е', 'и')
words = [] # Списък с шифрираните думи
for word in message.split():
# Отделяне на символите, различни от буква, в началото на думата:
prefixNonLetters = ''
while len(word) > 0 and not word[0].isalpha():
prefixNonLetters += word[0]
word = word[1:]
if len(word) == 0:
words.append(prefixNonLetters)
continue
# Отделяне на символите, различни от буква, в края на думата:
suffixNonLetters = ''
while not word[-1].isalpha():
suffixNonLetters += word[-1]
word = word[:-1]
# Запомнянв дали думата е изцяло от главни букви или започва с главна буква
wasUpper = word.isupper()
wasTitle = word.istitle()
word = word.lower() # всички букви се пробразуват в малки за щифрирането
# Отделяне на съгласните в началото на думата:
prefixConsonants = ''
while len(word) > 0 and not word[0] in VOWELS:
prefixConsonants += word[0]
word = word[1:]
# Добавяне на подходящ край на думата
if prefixConsonants != '':
word += prefixConsonants + 'ей'
else:
word += 'йей'
# Връщане на главните букви в думата
if wasUpper:
word = word.upper()
if wasTitle:
word = word.title()
# Добавяне на небуквените символи в началото и края на думата.
words.append(prefixNonLetters + word + suffixNonLetters)
# Слепване на всички думи в един низ:
print(' '.join(words))
Следва коментар на кода ред по ред:
# Шифроване на съобщение
print('Въведи съобщение, което да се шифрова:')
message = input()
VOWELS = ('а', 'ъ', 'о', 'у', 'е', 'и')
На потребителя се показва съобщение да въведе текст, който да се шифрира. Също така се създава константа, която съдържа всички малки гласни букви в комплект от низове. Използва се по-късно.
След това се създава променливата words, в която се добавят шифрираните думи
words = [] # Списък с шифрираните думи
for word in message.split():
# Отделяне на символите, различни от буква, в началото на думата:
prefixNonLetters = ''
while len(word) > 0 and not word[0].isalpha():
prefixNonLetters += word[0]
word = word[1:]
if len(word) == 0:
words.append(prefixNonLetters)
continue
необходимо е всяка дума да е отделен стринг. За тази цел се използва message.split(). Низът 'Моето име е СТАНИМИР и съм на 4000 години.' би бил разделен от split() на ['Моето', 'име', 'е', 'СТАНИМИР', 'и', 'съм', 'на', '4000', 'години.'].
След това трябва да се премахант всички небуквени символи в началото и края на всяка дума. Това се прави за правилното шифриране на низ като 'години.' до 'одинигей.', а не до 'одини.гей'. Небуквените символи в началото на думата се записват в променлива с име prefixNonLetters.
В цикъл се проверява първия символ на думата с isalpha(), като така се определя дали символът е буква. Ако не е - символът се премахва от думата и се добавя в края на prefixNonLetters. Може цялата дума да е съставена от небуквени символи, като '4000'. В такъв случай цялата дума се добавя директно в списъка words и се продължава със следващата дума за шифриране. По подобен начин трябва да се запазят и небуквените символи в края на думата. Кодът е подобен на предния цикъл:
# Отделяне на символите, различни от буква, в края на думата:
suffixNonLetters = ''
while not word[-1].isalpha():
suffixNonLetters += word[-1]
word = word[:-1]
След това програмата трябва да запомни дали думата е била с първа главна буква или изцяло с главни букви. Тази информация се използва за възстановяване на главните букви след шифрирането.
# Запомнянв дали думата е изцяло от главни букви или започва с главна буква
wasUpper = word.isupper()
wasTitle = word.istitle()
word = word.lower() # всички букви се пробразуват в малки за щифрирането
От тук до края на тялото на for цикъла се работи само с малки букви.
За шифрирането на дума като станимир в анимир-стей трябва да се премахнат всички съгласни в началото на word:
# Отделяне на съгласните в началото на думата:
prefixConsonants = ''
while len(word) > 0 and not word[0] in VOWELS:
prefixConsonants += word[0]
word = word[1:]
Използва цикъл, подобен на цикъла за премахване на небуквените символи в началото на word, само че сега се вземат съгласните и се запазват в променлива с име prefixConsonants.
В случай, че думата е започвала със съгласни, те са в prefixConsonants, така че трябва тази променлива да се добави в края на думата, следвана от низа 'ей'. Иначе думата е започвала с глсна и трябва да се добави само йей:
# Добавяне на подходящ край на думата
if prefixConsonants != '':
word += prefixConsonants + 'ей'
else:
word += 'йей'
Трябва да се помни, че думата е само с малки букви след word = word.lower(). Следващият код връща оrигиналния регистър на буквите (всички главни илил само първата главна):
# Връщане на главните букви в думата
if wasUpper:
word = word.upper()
if wasTitle:
word = word.title()
На края на цикъла for думата, заедно с небуквените символи пред и след нея, се добавят в списъка words:
# Добавяне на небуквените символи в началото и края на думата.
words.append(prefixNonLetters + word + suffixNonLetters)
# Слепване на всички думи в един низ:
print(' '.join(words))
След завършването на цикъла всички елементи в списъка words се комбинират в един низ с извикване на метода join(). Този низ се подава на функцията print() за показване на шифрираното съобщение.
Обобщение
Данните често са в текстов формат. Python има множество полезни низови методи, с които да се обработи текста в низ. В почти всяка Python програма се използва индексиране, разрязване и извикване на низови методи.
Програмите до тук не изглеждат много изтънчени - те нямат графичен потребителски интерфейс с картинки и цветен текст. Те показват текст с print() и позволяват на потребителя да въведе текст с input(). Все пак потребителят може бързо да въведе голям обем текст чрез копиране. Тази възможност позволява писането на програми, които обработват огромно количество текст. Такива текстови програми нямат красиви прозорци или графика, но вършат бързо много полезна работа.
Друг начин за обработка на големи количества текст е с четене и записване на файлове на хард диска. Това се обсъжда в Глава 9.
Това горе-долу покрива всички основи на Python програмирането! До края на тази книга могат да се научат още идеи, но вече има достатъчно знания за писане на полезни програми, които автоматизират задачи.
Може да няма достатъчно знания за писане на програми, които свалят уеб станици, променят електронни таблици или изпращат текстови съобщения, но за това са модулите на Python! Такива модули, написани от други програмисти, съдържат функции, които улесняват извършването на посочените задачи. Започва писането на реални програми, които автоматизират истински задачи.
Упражнения - въпроси
- Какво е екраниращ символ?
- Какво представят екраниращите символи \n и \t?
- Как може да се добави обратна наклонена черта \ в низ?
- Низовата стойност "д'Артанян е в замъка" е валиден низ. Защо единичната кавичка в думата д'Артанян не е екранирана?
- Как може в низ да има нови редове, ако не се използва \n?
- До какво се пресмятат следните изрази?
- 'Здравей, свят!'[1]
- 'Здравей, свят!'[0:7]
- 'Здравей, свят!'[:7]
- 'Здравей, свят!'[4:]
- До какво се пресмятат следните изрази?
- 'Здравей'.upper()
- 'Здравей'.upper().isupper()
- 'Здравей'.upper().lower()
- До какво се пресмятат следните изрази?
- 'Онче бонче, счупено пиронче'.split()
- '-'.join('Може да има само един.'.split())
- Кои низови методи се използва за подравняване и центриране на низ?
- Как могат да се премахнат невидимите символи в началото или в края на низ?
Практически упражнения
Да се напишат програми, които да вършат следните задачи.
Принтиране на таблица
Да се напише функция с име printTable(), която приема списък от списъци с низове и ги принтира в табличен вид. Всяка колона да е дясно подравнена. Всички вътрешни списъци ще са с еднакъв брой низове. Примерна стойност:
tableData = [['ябълки', 'круши', 'череши', 'портокали'],
['Анелия', 'Боби', 'Васил', 'Драго'],
['котки', 'кучета', 'мишки', 'елени']]
Функцията printTable() трябва да принтира следното:
ябълки Анелия котки
круши Боби кучета
череши Васил мишки
портокали Драго елени
Подсказка: кодът трябва да намери най-дългия низ от всеки вътрешен списък. Така може да се разбере ширината на колоната, за да побере всеки от низовете. Максималните ширини на колоните могат да се пазят в списък от целочислени стойности. Функцията printTable() може да започне с colWidths = [0] * let(tableData), което ще създаде списък, съдържащ толкова стойности 0, колкото е броят на списъците в tableData. По този начин colWidths[0] ще е ширината на най-дългия низ в tableData[0], colWidths[1] ще съдържа ширината на най-дългия низ в tableData[1] и така нататък. След това най-голямата стойност в списъка colWidths може да се подаде на низовия метод rjust().
Ботове за "Зомби зарове"
При игрите има жанр Игри за програмисти. В тях играчите не играят директно, а пишат програми "ботове", които да играят самостоятелно. Създаден е симулатор за играта "Зомби зарове", който позволява упражняване на създаването на изкуствен интелект, играещ игри. Ботовете за "Зомби зарове" могат да бъдат прости или невероятно сложни, което ги прави чудесни за групови или индивидуални упражнения.
"Зомби зарове" е бърза и забавна игра със зарове на компанията Steve Jackson Games. Играчите се превъплъщават в зомбита, опитващи да изядат колкото може повече човешки мозъци, без да ги прострелят три пъти. Има чашка с 13 зара. На страните на всеки зар има изобразени мозък (brains), стъпки (footsteps) или пушка(shotgun). Изображенията са оцветени, като всеки цвят носи различно разпределение на вероятностите. Всеки зар има по две страни със стъпки. Зар със зелени изображения има повече страни с мозък, с червени изображения има повече пушки, а жълтите зарове са с равен на брой мозъкци и пушки. Всеки ход на играч се състои от:
- В чашата се слагат всички 13 зара. Играчът тегли три случайни зара от чашата и ги хвърля. Играчът хвърля винаги по три зара.
- Преброяват се и се отделят падналите се мозъци и пушки. Събирането на три пушки автоматично приключва хода на играча с нула точки (без значение колко мозъка има). Ако играчът има между нула и 2 пушки може да избере да хвърля още. Може да избере да приключи хода си, като записва по една точка за всеки мозък.
- Ако играчът избере да хвърля наново, той трябва да хвърли всички зарове със стъпки. Играчът винаги трябва да хвърля по три зара. Той трябва да изтегли още зарове, ако са останали по-малко от три зара със стъпки за ново хвърляне. Играчът може да хвърля наново, докато не получи три пушки - губейки всичко, или всички 13 зара са хвърлени. Играчът не може да хвърли наново само един или два зара.
- Играта приключва, когато играч достигне 13 мозъка. В такъв случай останалите играчи довършват хода си в този кръг. Играчът с най-много събрани мозъци печели. При равенство играчите с равни точки играят още един тайбрек кръг.
"Зомби зарове" е хазартен тип игра - колкото повече зарове се хвърлят се увеличава вероятността за събиране на повече мозъци, но и вероятността за достигане на три пушки и загуба на всичко. След като някой играч достигне 13 точки, останалите играчи правят своя ход (те могат да натрупат още точки) и играта приключва. Печели играчът с най-много точки. В интернет могат да се намерят пълните правила на играта.
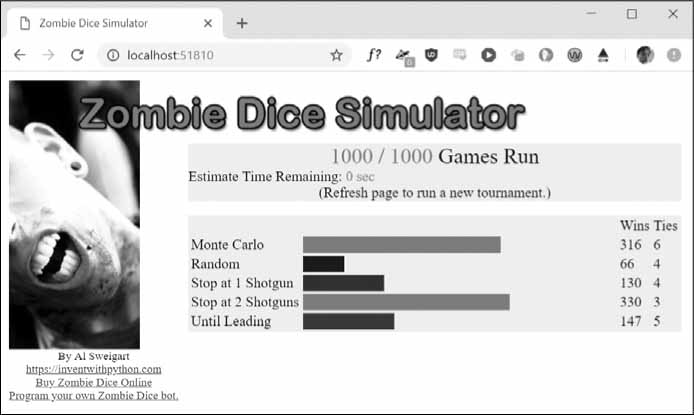
Трябва да се инсталира модула zombiedice според инструкциите в Допълнение А. Симулаторът има демо режим, който играе с предварително направени ботове. Този режим е пуска по следния начин:
>>> import zombiedice
>>> zombiedice.demo()
Zombie Dice Visualization is running. Open your browser to http://localhost:54293 to view it.
Press Ctrl-C to quit.
Ботовете се създават с писане на калс, който има метод turn(). Този метод се извиква от симулатора, когато е ред на бота да хвърля затовете. Класовете не са предмет на тази книга, така че кодът за класа е вече създаден в програмата myzombie.py отдолу. Писането на метод е на практика същото като писане на функция. За пример може да се започне с метода turn() от програмата myzombie.py. В този turn() метод се извиква функцията zombiedice.roll() за всяко хвърляне на заровете.
import zombiedice
class MyZombie:
def __init__(self, name):
# Всички зомбита трябва да имат име:
self.name = name
def turn(self, gameState):
# gameState е речник с информация за текущото състояние на играта.
# Може да се игнорира в кода
diceRollResults = zombiedice.roll() # първо хвърляне
# roll() връща речник с ключове 'brains' (мозъци),
# 'shotgun' (пушка) и 'footsteps' (стъпки) със стойност
# броя на падналите се изображения.
# С ключ 'rolls' е списък от комплекти (цвят, изображение)
# описващи какво точно е станало при хвърлянето
# Примерна върната стойност от roll():
# {'brains': 1, 'footsteps': 1, 'shotgun': 1,
# rolls: [('yellow', 'brains'), ('red', 'footsteps'),
# ('green', 'shotgun')]}
# Този примерен код трябва да се замени:
brains = 0
while diceRollResults is not None:
brains += diceRollResults['brains']
if brains < 2:
diceRollResults = zombiedice.roll() # ново хвърляне
else:
break
zombies = (
zombiedice.examples.RandomCoinFlipZombie(name='Random'),
zombiedice.examples.RollsUntilInTheLeadZombie(name='Until Leading'),
zombiedice.examples.MinNumShotgunsThenStopsZombie(name='Stop at 2 Shotguns', minShotguns=2),
zombiedice.examples.MinNumShotgunsThenStopsZombie(name='Stop at 1 Shotgun', minShotguns=1),
MyZombie(name='My Zombie Bot'),
# тук могат да се добавят още ботове
)
# Първият ред пуска симулатора в конзолата, а втория в уеб.
# Може да се използва който и да е от двата.
zombiedice.runTournament(zombies=zombies, numGames=1000)
#zombiedice.runWebGui(zombies=zombies, numGames=1000)
Методът turn() приема два параметъра: self и gameState. Те могат да се игнорират в първите ботове. В онлайн документацията има подробности за тези параметри. Методът turn() трябва да извика zombiedice.roll() поне веднъж за първоначалното хвърляне. След това извикването на zombiedice.roll() става според стратегията на бота. В примерния код zombiedice.roll()се извиква, доакто не се получат поне две точки.
Върнатата от zombiedice.roll() стойност съдържа резултатът от хвърляенто на заровете. Представлява речник с четири ключа. Три от ключовете ('shotgun', 'brains', 'footsteps') има целочислена стойност, съответстваща на броя зарове с това изображение. Четвъртият ключ ('rolls') има за стойност списък с комплект за всеки хвърлен зар. Комплектите съдържат два низа - цвета на зара под индекс 0 и полученото изображение под индекс 1. В коментарите в метода turn() има пример. zombiedice.roll() връща None при достигане на три пушки.
Да се напишат няколко бота, играещи "Зомби зарове", като се сравняват с другите ботове. Да се създадат следните ботове:
- Бот, който след първото хвърляне по случаен начин избира дали да продължи или не
- Бот, който приключва хода след като получи два мозъка
- Бот, който приключва хода след като получи две пушки
- Бот, който в началото решава по случаен начин да хвърля от един до четири пъти. Да прекратява хода, ако получи две пушки
- Бот, който приключва хода след като получи повече пушки от мозъци
Симулаторът помага за сравняване на ботовете. Кодът на някои предварително направени ботове е достъпен на адрес https://github.com/asweigart/zombiedice/. След хиляди симулирани игри може да се види, че една от най-добрите стратегии е да се спре при достигане на две пушки. Но винаги човек може да си пробва късмета ...
Подкрепете автора чрез покупка на оригиналната книга от No Starch Press или Amazon.